Overview of AMReX GPU Support
AMReX’s GPU support focuses on providing performance portability across a range of important architectures with minimal code changes required at the application level. This allows application teams to use a single, maintainable codebase that works on a variety of platforms while allowing for the performance tuning of specific, high-impact kernels if desired.
Internally, AMReX uses the native programming languages for GPUs: CUDA for NVIDIA, HIP
for AMD and SYCL for Intel. This will be designated with CUDA/HIP/SYCL
throughout the documentation. However, application teams can also use
OpenACC or OpenMP in their individual codes.
At this time, AMReX does not support cross-native language compilation (HIP for non-AMD systems and SYCL for non Intel systems). It may work with a given version, but AMReX does not track or guarantee such functionality.
AMReX uses an MPI+X approach to hierarchical parallelism. When running on
CPUs, X is OpenMP, and threads are used to process tiles assigned to the
same MPI rank concurrently, as detailed in MFIter with Tiling. On GPUs,
X is one of CUDA/HIP/SYCL, and tiling is disabled by default
to mitigate the overhead associated with kernel launching. Instead, kernels are usually
launched at the Box level, and one or more cells
in a given Box are mapped to each GPU thread, as detailed in Table 12
below.
Presented here is an overview of important features of AMReX’s GPU strategy. Additional information that is required for creating GPU applications is detailed throughout the rest of this chapter:
Each MPI rank offloads its work to a single GPU. Multiple ranks can share the same device, but for best performance we usually recommend
(MPI ranks == Number of GPUs).To provide performance portability, GPU kernels are usually launched through
ParallelForlooping constructs that use GPU extended lambdas to specify the work to be performed on each loop element. When compiled with GPU support, these constructs launch kernels with a large number of GPU threads that only work on a few cells each. This work distribution is illustrated in Table 12.
|
|
OpenMP tiled box. OpenMP threads break down the valid box into two large boxes (blue and orange). The lo and hi of one tiled box are marked. |
GPU threaded box. Each GPU thread works on a few cells of the valid box. This example uses one cell per thread, each thread using a box with lo = hi. |
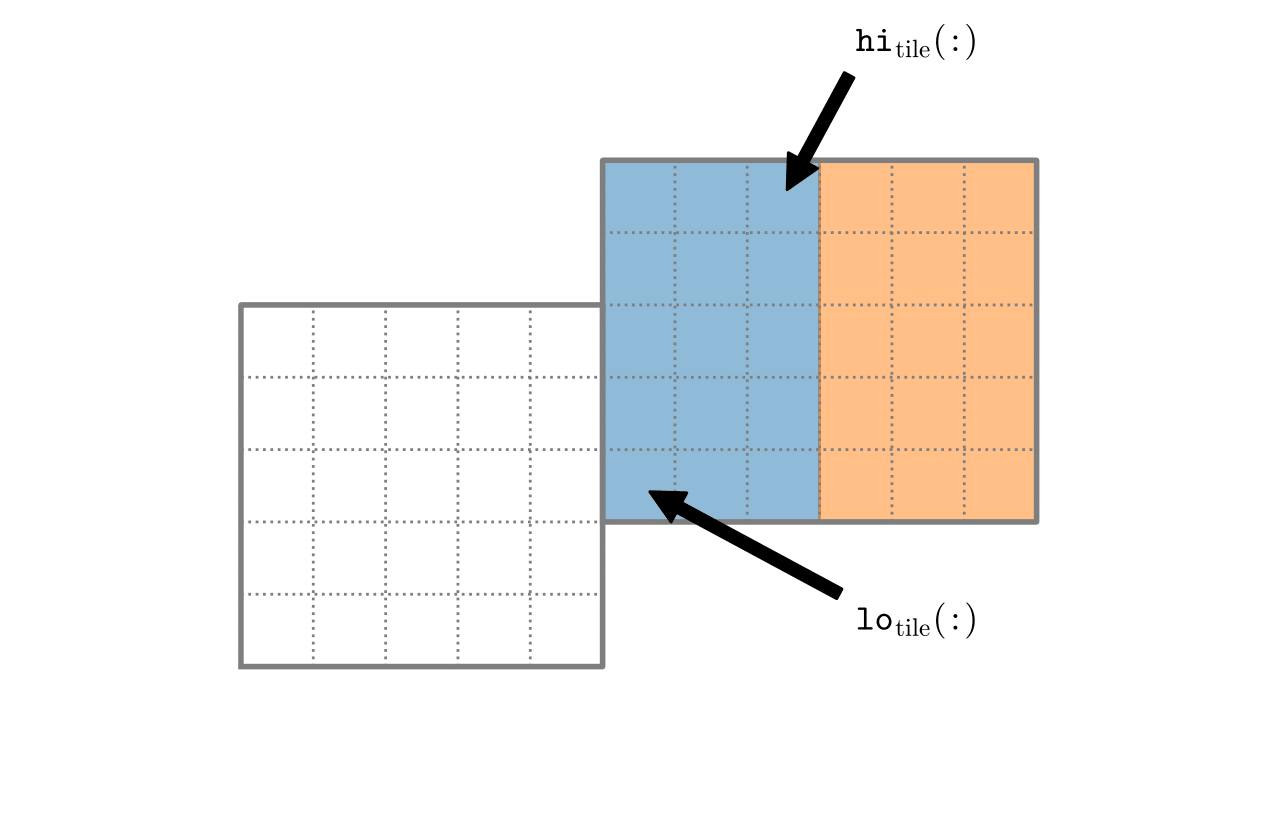
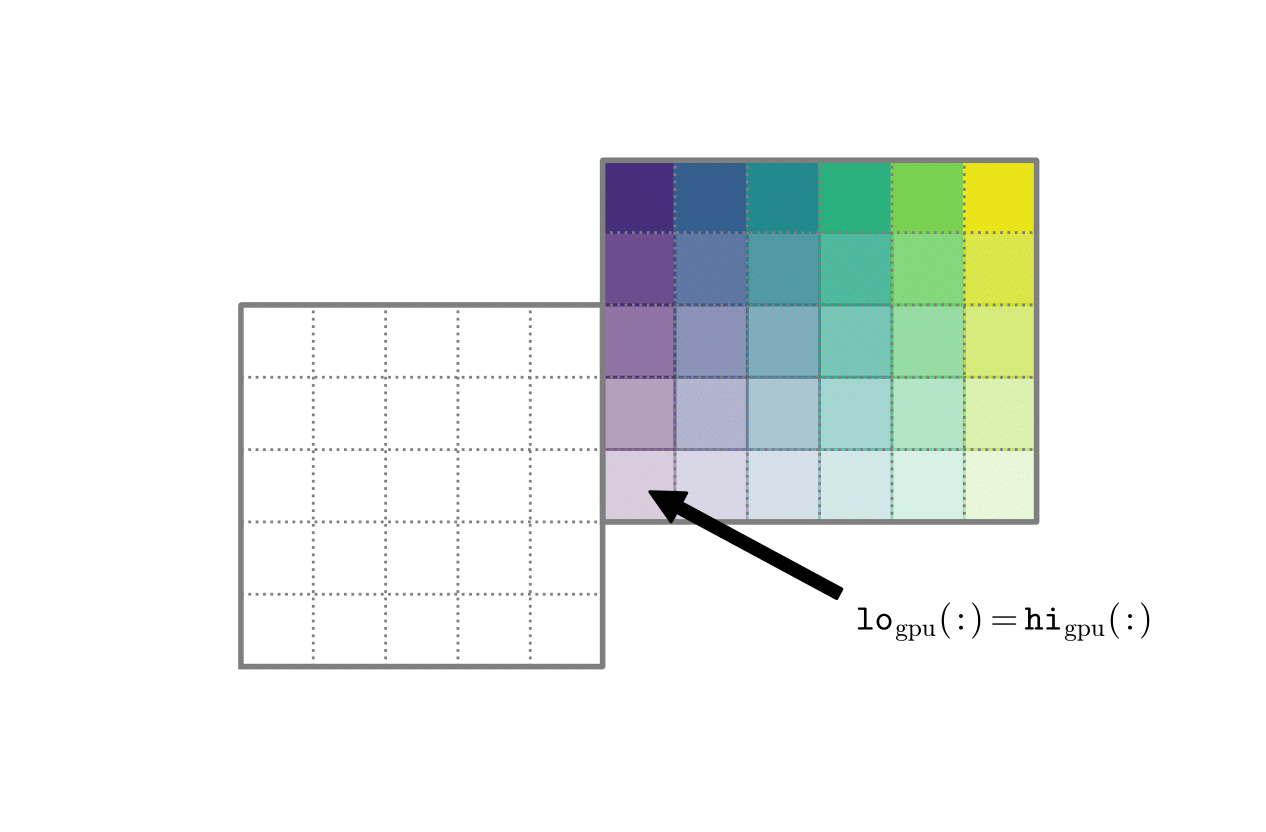
These kernels are usually launched inside AMReX’s
MFIterandParIterloops, since in AMReX’s approach to parallelism it is assumed that separateBoxobjects can be processed independently. However, AMReX also provides aMultiFabversion ofParallelForthat can process an entire level worth ofBoxobjects in a single kernel launch when it is safe to do so.AMReX can utilize GPU managed memory to automatically handle memory movement for mesh and particle data. Simple data structures, such as
IntVects can be passed by value and complex data structures, such asFArrayBoxes, have specialized AMReX classes to handle the data movement for the user. This is particularly useful for the early stages of porting an application to GPUs. However, for best performance on a variety of platforms, we recommend disabling managed memory and handling host/device data migration explicitly. managed memory is not used byFArrayBoxandMultiFabby default.Best performance is usually achieved when keeping mesh and particle data structures on the GPU for as long as possible, minimizing movement back to the CPU. In many AMReX applications, the mesh and particle data can stay on the GPU for most subroutines except for I/O operations.
AMReX further parallelizes GPU applications by utilizing streams. Streams guarantee execution order of kernels within the same stream, while allowing different streams to run simultaneously. AMReX places each iteration of
MFIterloops on separate streams, allowing each independent iteration to be run simultaneously and sequentially, while maximizing GPU usage.The AMReX implementation of streams is illustrated in Fig. 13. The CPU runs the first iteration of the MFIter loop (blue), which contains three GPU kernels. The kernels begin immediately in GPU Stream 1 and run in the same order they were added. The second (red) and third (green) iterations are similarly launched in Streams 2 and 3. The fourth (orange) and fifth (purple) iterations require more GPU resources than remain, so they have to wait until resources are freed before beginning. Meanwhile, after all the loop iterations are launched, the CPU reaches a synchronize in the MFIter’s destructor and waits for all GPU launches to complete before continuing.
The Fortran interface of AMReX does not currently have GPU support. AMReX recommends porting Fortran code to C++ when coding for GPUs.
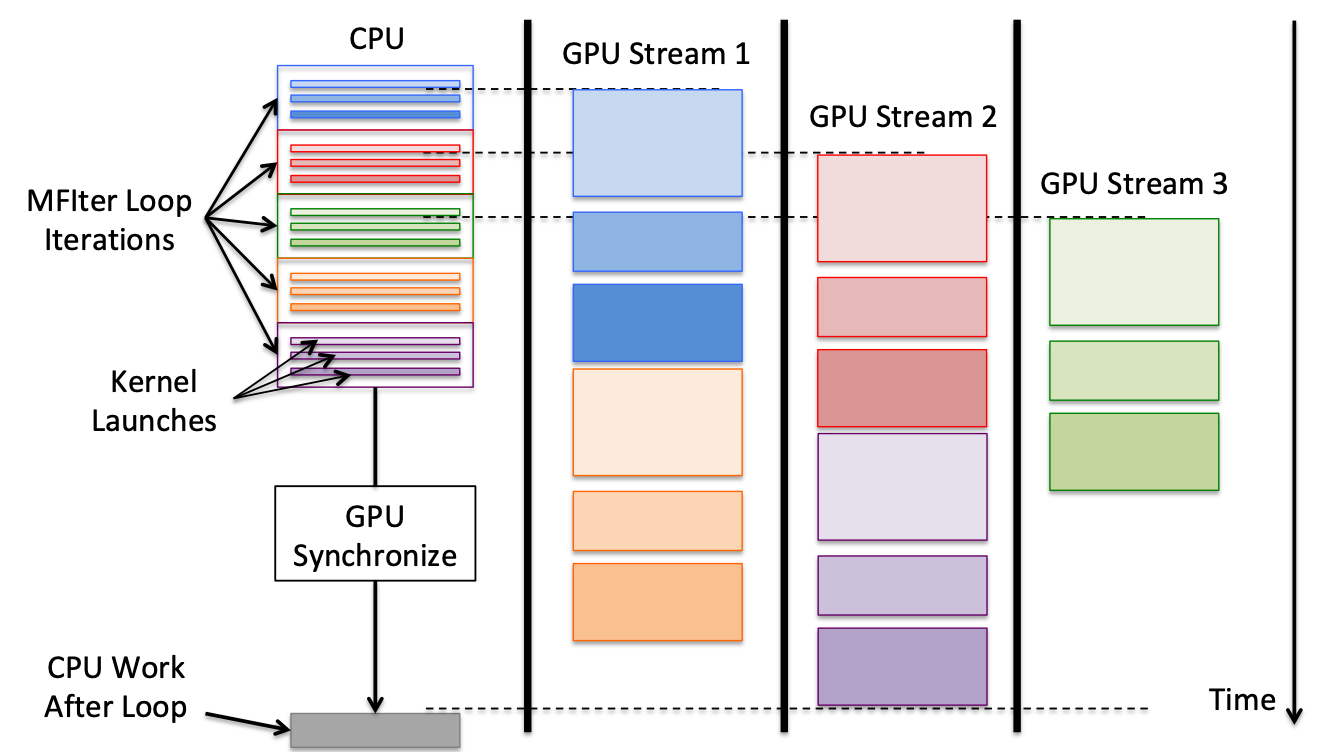
Fig. 13 Timeline illustration of GPU streams. Illustrates the case of an MFIter loop of five iterations with three GPU kernels each being run with three GPU streams.
Building GPU Support
Building with GNU Make
To build AMReX with GPU support, add USE_CUDA=TRUE, USE_HIP=TRUE or
USE_SYCL=TRUE to the GNUmakefile or as a command line argument.
AMReX does not require OpenACC, but application codes
can use them if they are supported by the compiler. For OpenACC support, add
USE_ACC=TRUE. PGI, Cray and GNU compilers support OpenACC. Thus,
for OpenACC, you must use COMP=pgi, COMP=cray or COMP=gnu.
Currently, only IBM is supported with OpenMP offloading. To use OpenMP
offloading, make with USE_OMP_OFFLOAD=TRUE.
Compiling AMReX with CUDA requires compiling the code through NVIDIA’s
CUDA compiler driver in addition to the standard compiler. This driver
is called nvcc and it requires a host compiler to work through.
The default host compiler for NVCC is GCC even if COMP is set to
a different compiler. One can change this by setting NVCC_HOST_COMP.
For example, COMP=pgi alone will compile C/C++ codes with NVCC/GCC
and Fortran codes with PGI, and link with PGI. Using COMP=pgi and
NVCC_HOST_COMP=pgi will compile C/C++ codes with PGI and NVCC/PGI.
You can use amrex-tutorials/ExampleCodes/Basic/HelloWorld_C/
to test your programming environment. For example, building with:
make COMP=gnu USE_CUDA=TRUE
should produce an executable named main3d.gnu.DEBUG.CUDA.ex. You
can run it and that will generate results like:
$ ./main3d.gnu.DEBUG.CUDA.ex
Initializing CUDA...
CUDA initialized with 1 GPU
AMReX (19.06-404-g0455b168b69c-dirty) initialized
Hello world from AMReX version 19.06-404-g0455b168b69c-dirty
Total GPU global memory (MB): 6069
Free GPU global memory (MB): 5896
[The Arena] space (MB): 4552
[The Managed Arena] space (MB): 8
[The Pinned Arena] space (MB): 8
AMReX (19.06-404-g0455b168b69c-dirty) finalized
SYCL configuration variables
When building with USE_SYCL=TRUE, one can set the following makefile
variables to configure the build
Variable Name |
Description |
Default |
Possible values |
|---|---|---|---|
SYCL_AOT |
Enable SYCL ahead-of-time compilation |
FALSE |
TRUE, FALSE |
SYCL_AOT_GRF_MODE |
Specify AOT register file mode |
Default |
Default, Large, AutoLarge |
AMREX_INTEL_ARCH |
Specify target if AOT is enabled |
None |
pvc, etc. |
SYCL_SPLIT_KERNEL |
Enable SYCL kernel splitting |
FALSE |
TRUE, FALSE |
USE_ONEDPL |
Enable SYCL’s oneDPL algorithms |
NO |
YES, NO |
SYCL_SUB_GROUP_SIZE |
Specify subgroup size |
32 |
64, 32, 16 |
SYCL_PARALLEL_LINK_JOBS |
Number of parallel jobs in device link |
1 |
1, 2, 3, etc. |
Building with CMake
To build AMReX with GPU support in CMake, add
-DAMReX_GPU_BACKEND=CUDA|HIP|SYCL to the cmake invocation, for CUDA,
HIP and SYCL, respectively. By default, AMReX uses 256 threads per GPU
block/group in most situations. This can be changed with
-DAMReX_GPU_MAX_THREADS=N, where N is 128 for example.
Enabling CUDA support
To build AMReX with CUDA support in CMake, add -DAMReX_GPU_BACKEND=CUDA to the
cmake invocation. For a full list of CUDA-specific configuration options,
check the table below.
Variable Name |
Description |
Default |
Possible values |
|---|---|---|---|
AMReX_CUDA_ARCH |
CUDA target architecture |
Auto |
User-defined |
AMReX_CUDA_FASTMATH |
Enable CUDA fastmath library |
YES |
YES, NO |
AMReX_CUDA_BACKTRACE |
Host function symbol names (e.g. cuda-memcheck) |
Auto |
YES, NO |
AMReX_CUDA_COMPILATION_TIMER |
CSV table with time for each compilation phase |
NO |
YES, NO |
AMReX_CUDA_DEBUG |
Device debug information (optimizations: off) |
YES: Debug |
YES, NO |
AMReX_CUDA_ERROR_CAPTURE_THIS |
Error if a CUDA lambda captures a class’ this |
NO |
YES, NO |
AMReX_CUDA_ERROR_CROSS _EXECUTION_SPACE_CALL |
Error if a host function is called from a host device function |
NO |
YES, NO |
AMReX_CUDA_KEEP_FILES |
Keep intermediate files (folder: nvcc_tmp) |
NO |
YES, NO |
AMReX_CUDA_OBJDIR_AS_TEMPDIR |
Place intermediate files in object file folder |
NO |
YES, NO |
AMReX_CUDA_LTO |
Enable CUDA link-time-optimization |
NO |
YES, NO |
AMReX_CUDA_MAXREGCOUNT |
Limits the number of CUDA registers available |
255 |
User-defined |
AMReX_CUDA_PTX_VERBOSE |
Verbose code generation statistics in ptxas |
NO |
YES, NO |
AMReX_CUDA_SHOW_CODELINES |
Source information in PTX (optimizations: on) |
Auto |
YES, NO |
AMReX_CUDA_SHOW_LINENUMBERS |
Line-number information (optimizations: on) |
Auto |
YES, NO |
AMReX_CUDA_WARN_CAPTURE_THIS |
Warn if a CUDA lambda captures a class’ this |
YES |
YES, NO |
The target architecture to build for can be specified via the configuration option
-DAMReX_CUDA_ARCH=<target-architecture>, where <target-architecture> can be either
the name of the NVIDIA GPU generation, e.g., Turing, Volta, or Ampere, or its
compute capability, e.g., 10.0 or 9.0.
For example, on Cori GPUs you can specify the architecture as follows:
cmake [options] -DAMReX_GPU_BACKEND=CUDA -DAMReX_CUDA_ARCH=Volta /path/to/amrex/source
If no architecture is specified, CMake will default to the architecture defined in the
environment variable AMREX_CUDA_ARCH (note: all caps).
If the latter is not defined, CMake will try to determine which GPU architecture is supported by the system.
If more than one is found, CMake will build for all of them.
If autodetection fails, a list of “common” architectures is assumed.
Multiple CUDA architectures can also be set manually as a semicolon-separated list, e.g., -DAMReX_CUDA_ARCH=7.0;8.0.
Building for multiple CUDA architectures will generally result in a larger library and longer build times.
Note that AMReX supports NVIDIA GPU architectures with compute capability 6.0 or higher and CUDA Toolkit version 12.2 or higher.
In order to import the CUDA-enabled AMReX library into your CMake project, you need to include the following code into the appropriate CMakeLists.txt file:
# Find CUDA-enabled AMReX installation
find_package(AMReX REQUIRED CUDA)
If instead of using an external installation of AMReX you prefer to include AMReX as a subproject
in your CMake setup, we strongly encourage you to use the AMReX_SetupCUDA module as shown below
if the CMake version is less than 3.20:
# Enable CUDA in your CMake project
enable_language(CUDA)
# Include the AMReX-provided CUDA setup module -- OBSOLETE with CMake >= 3.20
if(CMAKE_VERSION VERSION_LESS 3.20)
include(AMReX_SetupCUDA)
endif()
# Include AMReX source directory ONLY AFTER the two steps above
add_subdirectory(/path/to/amrex/source/dir)
To ensure consistency between CUDA-enabled AMReX and any CMake target that links against it,
we provide the helper function setup_target_for_cuda_compilation():
# Set all sources for my_target
target_sources(my_target source1 source2 source3 ...)
# Setup my_target to be compiled with CUDA and be linked against CUDA-enabled AMReX
# MUST be done AFTER all sources have been assigned to my_target
setup_target_for_cuda_compilation(my_target)
# Link against amrex
target_link_libraries(my_target PUBLIC AMReX::amrex)
Enabling HIP Support
To build AMReX with HIP support in CMake, add
-DAMReX_GPU_BACKEND=HIP -DAMReX_AMD_ARCH=<target-arch> -DCMAKE_CXX_COMPILER=<your-hip-compiler>
to the cmake invocation.
If you don’t need Fortran features (AMReX_FORTRAN=OFF), it is recommended to use AMD’s clang++ as the HIP compiler.
(Please see these issues for reference in rocm/HIP <= 4.2.0
[1]
[2].)
In AMReX CMake, the HIP compiler is treated as a special C++ compiler and therefore
the standard CMake variables used to customize the compilation process for C++,
for example CMAKE_CXX_FLAGS, can be used for HIP as well.
Since CMake does not support autodetection of HIP compilers/target architectures
yet, CMAKE_CXX_COMPILER must be set to a valid HIP compiler, i.e. clang++ or hipcc,
and AMReX_AMD_ARCH to the target architecture you are building for.
Thus AMReX_AMD_ARCH and CMAKE_CXX_COMPILER are required user inputs when AMReX_GPU_BACKEND=HIP.
We also read the environment variable AMREX_AMD_ARCH (note: all caps), and the C++ compiler can be specified as usual, e.g., with export CXX=$(which clang++).
Below is an example configuration for HIP on Tulip:
cmake -S . -B build -DAMReX_GPU_BACKEND=HIP -DCMAKE_CXX_COMPILER=$(which clang++) -DAMReX_AMD_ARCH="gfx906;gfx908" # [other options]
cmake --build build -j 6
Enabling SYCL Support
To build AMReX with SYCL support in CMake, add
-DAMReX_GPU_BACKEND=SYCL -DCMAKE_CXX_COMPILER=<your-sycl-compiler>
to the cmake invocation.
For a full list of SYCL-specific configuration options,
check the table below.
In AMReX CMake, the SYCL compiler is treated as a special C++ compiler and therefore
the standard CMake variables used to customize the compilation process for C++,
for example CMAKE_CXX_FLAGS, can be used for SYCL as well.
Since CMake does not support autodetection of SYCL compilers yet,
CMAKE_CXX_COMPILER must be set to a valid SYCL compiler, i.e., icpx.
Thus CMAKE_CXX_COMPILER is a required user-input when AMReX_GPU_BACKEND=SYCL.
At this time, the only supported SYCL compiler is icpx.
Below is an example configuration for SYCL:
cmake -DAMReX_GPU_BACKEND=SYCL -DCMAKE_CXX_COMPILER=$(which icpx) [other options] /path/to/amrex/source
Variable Name |
Description |
Default |
Possible values |
|---|---|---|---|
AMReX_SYCL_AOT |
Enable SYCL ahead-of-time compilation |
NO |
YES, NO |
AMReX_SYCL_AOT_GRF_MODE |
Specify AOT register file mode |
Default |
Default, Large, AutoLarge |
AMREX_INTEL_ARCH |
Specify target if AOT is enabled |
None |
pvc, etc. |
AMReX_SYCL_SPLIT_KERNEL |
Enable SYCL kernel splitting |
YES |
YES, NO |
AMReX_SYCL_ONEDPL |
Enable SYCL’s oneDPL algorithms |
NO |
YES, NO |
AMReX_SYCL_SUB_GROUP_SIZE |
Specify subgroup size |
32 |
64, 32, 16 |
AMReX_PARALLEL_LINK_JOBS |
Specify number of parallel link jobs |
1 |
positive integer |
Gpu Namespace and Macros
Most GPU related classes and functions are in namespace Gpu,
which is inside namespace amrex. For example, the GPU configuration
class Device can be referenced to at amrex::Gpu::Device.
For portability, AMReX defines some macros for CUDA/HIP function qualifiers
and they should be preferred to allow execution when USE_CUDA=FALSE and
USE_HIP=FALSE.
These include:
#define AMREX_GPU_HOST __host__
#define AMREX_GPU_DEVICE __device__
#define AMREX_GPU_GLOBAL __global__
#define AMREX_GPU_HOST_DEVICE __host__ __device__
Note that when AMReX is not built with CUDA/HIP/SYCL,
these macros expand to empty space.
When AMReX is compiled with USE_CUDA=TRUE, USE_HIP=TRUE,
USE_SYCL=TRUE, or USE_ACC=TRUE the preprocessor
macros AMREX_USE_CUDA, AMREX_USE_HIP, AMREX_USE_SYCL,
or AMREX_USE_ACC respectively are defined for
conditional programming, as well as AMREX_USE_GPU.
This AMREX_USE_GPU definition can be used in application code
if different functionality should be used when AMReX is built with
GPU support.
When AMReX is compiled with USE_OMP_OFFLOAD=TRUE,
AMREX_USE_OMP_OFFLOAD is defined.
The macros AMREX_IF_ON_DEVICE((code_for_device)) and
AMREX_IF_ON_HOST((code_for_host)) should be used when a
__host__ __device__ function requires separate code for the
CPU and GPU implementations.
Memory Allocation
To provide portability and improve memory allocation performance,
AMReX provides a number of memory pools. When compiled without
GPU support, all Arenas use standard new and delete
operators. With GPU support, the Arenas each allocate with a
specific type of GPU memory:
Arena |
Memory Type |
|---|---|
The_Arena() |
managed or device memory |
The_Device_Arena() |
device memory, could be an alias to The_Arena() |
The_Managed_Arena() |
managed memory, could be an alias to The_Arena() |
The_Pinned_Arena() |
pinned memory |
The Arena object returned by these calls provides access to two functions:
void* alloc (std::size_t sz);
void free (void* p);
The_Arena() is used for memory allocation of data in
BaseFab. By default, it allocates device memory. This can be changed with
a boolean runtime parameter amrex.the_arena_is_managed=1.
When managed memory is enabled, the data in a MultiFab is placed in
device memory by default and is accessible from both CPU host and GPU device.
This allows application codes to develop their GPU capability
gradually. The behavior of The_Managed_Arena() likewise depends on the
amrex.the_arena_is_managed parameter. If amrex.the_arena_is_managed=0,
The_Managed_Arena() is a separate pool of managed memory. If
amrex.the_arena_is_managed=1, The_Managed_Arena() is simply aliased
to The_Arena() to reduce memory fragmentation.
In amrex::Initialize, a large amount of GPU device memory is
allocated and is kept in The_Arena(). The default is 3/4 of the
total device memory, and it can be changed with a ParmParse
parameter, amrex.the_arena_init_size, in the unit of bytes. The default
can also be changed with an environment variable
AMREX_THE_ARENA_INIT_SIZE=X, where X is the number of bytes. When
both the ParmParse parameter and the environment variable are
present, the former will override the latter. In both cases, the number
string could have optional single quotes ' as separators (e.g.,
10'000'000'000). It may also use floating-point notation (2.5e10),
as long as converting it does not introduce any loss of precision.
The default initial size for other arenas is 8388608 (i.e., 8 MB). For
The_Managed_Arena() and The_Device_Arena(), it can be changed
with amrex.the_managed_arena_init_size and
amrex.the_device_arena_init_size, respectively, if they are not an alias
to The_Arena(). For The_Pinned_Arena(), it can be changed
with amrex.the_pinned_arena_init_size. The user can also specify a
release threshold for these arenas. If the memory usage in an arena is
below the threshold, the arena will keep the memory for later reuse,
otherwise it will try to release memory back to the system if it is not
being used. By default, the release threshold for The_Arena() is set
to be a huge number that prevents the memory being released automatically,
and it can be changed with a parameter,
amrex.the_arena_release_threshold. For The_Pinned_Arena(), the
default release threshold is the size of the total device memory, and the
runtime parameter is amrex.the_pinned_arena_release_threshold. If it is
a separate arena, the behavior of The_Device_Area() or
The_Managed_Arena() can be changed with
amrex.the_device_arena_release_threshold or
amrex.the_managed_arena_release_threshold. Note that the units for all
the parameter discussed above are bytes. All these arenas also have a
member function freeUnused() that can be used to manually release
unused memory back to the system.
If you want to print out the current memory usage
of the Arenas, you can call amrex::Arena::PrintUsage().
When AMReX is built with SUNDIALS turned on, amrex::sundials::The_SUNMemory_Helper()
can be provided to SUNDIALS data structures so that they use the appropriate
Arena object when allocating memory. For example, it can be provided to the
SUNDIALS CUDA vector:
N_Vector x = N_VNewWithMemHelp_Cuda(size, use_managed_memory, *The_SUNMemory_Helper());
GPU Safe Classes and Functions
AMReX GPU work takes place inside of MFIter and ParIter loops. Therefore, there are two ways classes and functions have been modified to interact with the GPU:
1. A number of functions used within these loops are labeled using
AMREX_GPU_HOST_DEVICE and can be called on the device. This includes member
functions, such as IntVect::type(), as well as non-member functions,
such as amrex::min and amrex::max. In specialized cases,
classes are labeled such that objects can be constructed and destroyed
on the device, and their functions can be called there, including IntVect.
2. Functions that contain MFIter or ParIter loops have been rewritten
to contain device launches. For example, the FillBoundary
function cannot be called from device code, but calling it from
CPU will launch GPU kernels if AMReX is compiled with GPU support.
Necessary and convenient AMReX functions and objects have been given a device version and/or device access.
In this section, we discuss some examples of AMReX device classes and functions that are important for programming GPUs.
GpuArray, Array1D, Array2D, and Array3D
GpuArray, Array1D, Array2D, and Array3D are trivial types
that work on both host and device. They can be used whenever a fixed size array
needs to be passed to the GPU or created on GPU. A variety of
functions in AMReX return GpuArray and they can be
lambda-captured to GPU code. For example,
GeometryData::CellSizeArray(), GeometryData::InvCellSizeArray()
and Box::length3d() all return GpuArrays.
AsyncArray
Where the GpuArray is a statically-sized array designed to be
passed by value onto the device, AsyncArray is a
dynamically-sized array container designed to work between the CPU and
GPU. AsyncArray stores a CPU pointer and a GPU pointer and
coordinates the movement of an array of objects between the two. It
can take initial values from the host and move them to the device. It
can copy the data from device back to host. It can also be used as
scratch space on device.
The call to delete the memory is added to the GPU stream as a callback
function in the destructor of AsyncArray. This guarantees the
memory allocated in AsyncArray continues to exist after the
AsyncArray object is deleted when going out of scope until
after all GPU kernels in the stream are completed without forcing the
code to synchronize. The resulting AsyncArray class is
“async-safe”, meaning it can be safely used in asynchronous code
regions that contain both CPU work and GPU launches, including
MFIter loops.
AsyncArray is also portable. When AMReX is compiled without
GPU support, the object only stores and handles the CPU version of
the data.
An example using AsyncArray is given below,
Real h_s = 0.0;
AsyncArray<Real> aa_s(&h_s, 1); // Build AsyncArray of size 1
Real* d_s = aa_s.data(); // Get associated device pointer
for (MFIter mfi(mf); mfi.isValid(); ++mfi)
{
Vector<Real> h_v = a_cpu_function();
AsyncArray<Real> aa_v1(h_v.data(), h_v.size());
Real* d_v1 = aa_v1.data(); // A device copy of the data
std::size_t n = ...;
AsyncArray<Real> aa_v2(n); // Allocate temporary space on device
Real* d_v2 = aa_v2.data(); // A device pointer to uninitialized data
... // gpu kernels using the data pointed by d_v1 and atomically
// updating the data pointed by d_s.
// d_v2 can be used as scratch space and for pass data
// between kernels.
// If needed, we can copy the data back to host using
// AsyncArray::copyToHost(host_pointer, number_of_elements);
// At the end of each loop the compiler inserts a call to the
// destructor of aa_v* on cpu. Objects aa_v* are deleted, but
// their associated memory pointed by d_v* is not deleted
// immediately until the gpu kernels in this loop finish.
}
aa_s.copyToHost(&h_s, 1); // Copy the value back to host
Gpu Vectors
AMReX also provides a number of dynamic vectors for use with GPU kernels. These are configured to use the different AMReX memory Arenas, as summarized below. By using the memory Arenas, we can avoid expensive allocations and deallocations when (for example) resizing vectors.
Vector |
Arena |
|---|---|
DeviceVector |
The_Arena() |
HostVector |
The_Pinned_Arena() |
ManagedVector |
The_Managed_Arena() |
These classes behave almost identically to an
amrex::Vector, (see Vector, Array, GpuArray, Array1D, Array2D, and Array3D), except that they
can only hold “plain-old-data” objects (e.g. Reals, integers, amrex Particles,
etc… ). If you want a resizable vector that doesn’t use a memory Arena,
simply use amrex::Vector.
Note that, even if the data in the vector is managed and available on GPUs,
the member functions of e.g. Gpu::ManagedVector are not.
To use the data on the GPU, it is necessary to pass the underlying data pointer
in to the GPU kernels. The managed data pointer can be accessed using the data()
member function.
Be aware: resizing of dynamically allocated memory on the GPU is unsupported. All resizing of the vector should be done on the CPU, in a manner that avoids race conditions with concurrent GPU kernels.
Also note: Gpu::ManagedVector is not async-safe. It cannot be safely
constructed inside of an MFIter loop with GPU kernels and great care should
be used when accessing Gpu::ManagedVector data on GPUs to avoid race
conditions.
Gpu::Buffer, Gpu::ManagedVector, and Gpu::TrackedVector
Gpu::Buffer (AMReX_GpuBuffer.H) and Gpu::TrackedVector
(AMReX_TrackedVector.H) pair a host allocation with a device mirror.
Gpu::Buffer uses Gpu::PinnedVector on the host and
copyToDeviceAsync() / copyToHost() for transfers. Use it for
frequent, performance-oriented async copies during a normal GPU run.
Gpu::ManagedVector is the arena-backed unified-memory vector introduced
under Gpu Vectors above (The_Managed_Arena()). Like Gpu::Buffer
it can only be used while AMReX is initialized / a GPU device context exists.
Gpu::TrackedVector exposes a host std::vector via host() /
host_const() and a device Gpu::NonManagedDeviceVector via
device() / device_const() (GPU builds only). Every accessor automatically
synchronizes the other side when needed: if the host was modified and you
call device() or device_const(), a synchronous host-to-device copy
runs first (and vice versa). Writable accessors (host(), device())
additionally mark the returned side as dirty so that the next access to the
opposite side triggers a copy back. Read-only accessors
(host_const(), device_const()) leave the status as up_to_date
after syncing. You may populate the host before
amrex::Initialize(). Device memory is only valid while AMReX is
initialized. On amrex::Finalize(), AMReX clears device storage via
release_gpu() and leaves the host copy for reuse, which supports
Python / pyAMReX and other workflows that cross multiple AMReX
initialize/finalize cycles. Use read-only host_const() /
device_const() when you are not writing, so the object does not flip to a
dirty state unnecessarily.
|
|
|
|
|---|---|---|---|
Lifetime |
Only between |
Only between |
Anytime and cross-session, GPU part only between |
Usage |
|
Single |
Separate |
Synchronization |
explicit |
implicit |
automatic on access, tracks status |
Performance |
Best: pinned host enables asynchronous transfers |
Implicit memory migration can add latency |
Synchronous copy adds latency |
Best for |
hot copy loops inside a run |
maximum simplicity |
interactive and cross-AMReX session usage, e.g., in pyAMReX for user inputs that do not change often |
A minimal Gpu::Buffer pattern (host fill, async upload, kernel pointer):
amrex::Initialize(argc, argv);
Gpu::Buffer<int> buf(n);
for (int i = 0; i < n; ++i) { buf[i] = i; }
int* dp = buf.copyToDeviceAsync();
// launch kernels using dp, then optionally:
buf.copyToHost();
Gpu::ManagedVector example (unified memory, accessible from both host and device):
amrex::Initialize(argc, argv);
Gpu::ManagedVector<int> mv(n);
for (int i = 0; i < n; ++i) { mv[i] = i; }
int* dp = mv.data();
amrex::ParallelFor(n, [=] AMREX_GPU_DEVICE (int i) {
dp[i] *= 2; // access on device
});
Gpu::streamSynchronize();
// mv[i] now accessible on host with updated values
Gpu::TrackedVector example:
On GPU builds, you can create this type at any time, even before amrex::Initialize().
amrex::Finalize() releases device storage for the vector but
keeps the host std::vector, so a later Initialize() session
can access device_const() or device() and the host data is
automatically copied to the device.
// Host data before AMReX init; GPU available after Initialize().
amrex::Gpu::TrackedVector<int> cross_session;
cross_session.host() = {7, 8, 9};
// ... a lot of other interactive user code, e.g., to set up
// complex input data, optimization libraries or ML frameworks
// in multi-simulation workflows ...
amrex::Initialize(argc, argv);
{
// device access auto-syncs host data to device.
int const* dp = cross_session.device_const().data();
// use dp in kernels ...
}
amrex::Finalize();
// cross_session.device() is not available now and will throw,
// but you can keep using cross_session.host() / .host_const()
amrex::Initialize(argc, argv);
{
// Device buffer is re-created automatically on access.
int const* dp = cross_session.device_const().data();
// kernels may read via device_const().data()
// or write via device().data()
}
amrex::Finalize();
Optional: Call release_gpu() when you need to free device memory while
keeping the host std::vector for later (unless already released,
amrex::Finalize() clears device storage registered for the object).
Generally, after device kernels, call Gpu::streamSynchronize()
(or equivalent ordering) before relying on host data, as for any other device work.
MultiFab Reductions
AMReX provides functions for performing standard reduction operations on
MultiFabs, including MultiFab::sum and MultiFab::max.
When AMReX is built with GPU support, these functions automatically implement the
corresponding reductions on GPUs in an efficient manner.
Function template ParReduce can be used to implement user-defined
reduction functions over MultiFabs. For example, the following
function computes the sum of total kinetic energy using the data in a
MultiFab storing the mass and momentum density.
Real compute_ek (MultiFab const& mf)
{
auto const& ma = mf.const_arrays();
return ParReduce(TypeList<ReduceOpSum>{}, TypeList<Real>{},
mf, IntVect(0), // zero ghost cells
[=] AMREX_GPU_DEVICE (int box_no, int i, int j, int k)
noexcept -> GpuTuple<Real>
{
Array4<Real const> const& a = ma[box_no];
Real rho = a(i,j,k,0);
Real rhovx = a(i,j,k,1);
Real rhovy = a(i,j,k,2);
Real rhovz = a(i,j,k,3);
Real ek = (rhovx*rhovx+rhovy*rhovy+rhovz*rhovz)/(2.*rho);
return { ek };
});
}
As another example, the following function computes the max- and 1-norm of a
MultiFab in the masked region specified by an iMultiFab.
GpuTuple<Real,Real> compute_norms (MultiFab const& mf,
iMultiFab const& mask)
{
auto const& data_ma = mf.const_arrays();
auto const& mask_ma = mask.const_arrays();
return ParReduce(TypeList<ReduceOpMax,ReduceOpSum>{},
TypeList<Real,Real>{},
mf, IntVect(0), // zero ghost cells
[=] AMREX_GPU_DEVICE (int box_no, int i, int j, int k)
noexcept -> GpuTuple<Real,Real>
{
if (mask_ma[box_no](i,j,k)) {
Real a = std::abs(data_ma[box_no](i,j,k));
return { a, a };
} else {
return { 0., 0. };
}
});
}
It should be noted that the reduction result of ParReduce is local
and it is the user’s responsibility if MPI communication is needed.
Box, IntVect and IndexType
In AMReX, Box, IntVect and IndexType
are classes for representing indices. These classes and most of
their member functions, including constructors and destructors,
have both host and device versions. They can be used freely
in device code.
Geometry
AMReX’s Geometry class is not a GPU safe class. However, we often need
to use geometric information such as cell size and physical coordinates
in GPU kernels. We can use the following member functions and pass
the returned values to GPU kernels:
GpuArray<Real,AMREX_SPACEDIM> ProbLoArray () const noexcept;
GpuArray<Real,AMREX_SPACEDIM> ProbHiArray () const noexcept;
GpuArray<int,AMREX_SPACEDIM> isPeriodicArray () const noexcept;
GpuArray<Real,AMREX_SPACEDIM> CellSizeArray () const noexcept;
GpuArray<Real,AMREX_SPACEDIM> InvCellSizeArray () const noexcept;
Alternatively, we can copy the data into a GPU safe class that can be
passed by value to GPU kernels. This class is called
GeometryData, which is created by calling
Geometry::data(). The accessor functions of
GeometryData are identical to Geometry.
BaseFab, FArrayBox, IArrayBox
BaseFab<T>, IArrayBox and FArrayBox have some GPU
support. They cannot be constructed in device code unless they are
constructed as an alias to Array4. Many of their member
functions can be used in device code as long as they have been
constructed in device memory. Some of the device member functions
include array, dataPtr, box, nComp, and
setVal.
All BaseFab<T> objects in FabArray<FAB> are allocated in
CPU memory, including IArrayBox and FArrayBox, which are
derived from BaseFab, and the array data contained are
allocated in either device or managed memory. We cannot pass a BaseFab object by
value because they do not have copy constructor. However, we can make
an Array4 using member function BaseFab::array(), and pass it
by value to GPU kernels. In GPU device code, we can use Array4
or, if necessary, we can make an alias BaseFab from an
Array4. For example,
AMREX_GPU_HOST_DEVICE void g (FArrayBox& fab) { ... }
AMREX_GPU_HOST_DEVICE void f (Box const& bx, Array4<Real> const& a)
{
FArrayBox fab(a,bx.ixType());
g(fab);
}
Elixir
We often have temporary FArrayBoxes in MFIter loops.
These objects go out of scope at the end of each iteration. Because
of the asynchronous nature of GPU kernel execution, their destructors
might get called before their data are used on GPU. Elixir can
be used to extend the life of the data. For example,
for (MFIter mfi(mf); mfi.isValid(); ++mfi) {
const Box& bx = mfi.tilebox();
FArrayBox tmp_fab(bx, numcomps);
Elixir tmp_eli = tmp_fab.elixir();
Array4<Real> const& tmp_arr = tmp_fab.array();
// GPU kernels using the temporary
}
Without Elixir, the code above will likely cause memory errors
because the temporary FArrayBox is deleted on cpu before the
gpu kernels use its memory. With Elixir, the ownership of the
memory is transferred to Elixir that is guaranteed to be
async-safe.
Async Arena
Using a stream-ordered allocator, the temporary memory
allocation and deallocation issue discussed above can be solved.
Instead of using Elixir, we can write code like below,
for (MFIter mfi(mf); mfi.isValid(); ++mfi) {
const Box& bx = mfi.tilebox();
FArrayBox tmp_fab(bx, numcomps, The_Async_Arena());
Array4<Real> const& tmp_arr = tmp_fab.array();
// GPU kernels using the temporary
}
The freed memory is held in a buffer until the next time the GPU stream is synchronized.
In case too much memory is in this buffer, the stream is synchronized automatically.
This is now the recommended way because it’s usually more efficient than
Elixir. Note that the code above works on all platforms.
Kernel Launch
In this section, how to offload work to the GPU will be demonstrated. AMReX supports offloading work with CUDA, HIP, SYCL, OpenACC, or OpenMP.
When using CUDA, HIP, or SYCL, AMReX provides users with portable C++ function calls or C++ macros that launch a user-defined lambda function. When compiled without CUDA/HIP/SYCL, the lambda function is ran on the CPU. When compiled with CUDA/HIP/SYCL, the launch function prepares and launches the lambda function on the GPU. The preparation includes calculating the appropriate number of blocks and threads, selecting the CUDA stream or HIP stream or SYCL queue, and defining the appropriate work chunk for each GPU thread.
When using OpenACC or OpenMP offloading pragmas, the users add the appropriate pragmas to their work loops and functions to offload to the GPU. These work in conjunction with AMReX’s internal CUDA-based memory management, described earlier, to ensure the required data is available on the GPU when the offloaded function is executed.
The available launch schema are presented here in three categories: launching nested loops over Boxes or 1D arrays, launching generic work and launching using OpenACC or OpenMP pragmas. The latest versions of the examples used in this section of the documentation can be found in the AMReX source code in the Launch tutorials. Users should also refer to Chapter Basics as needed for information about basic AMReX classes.
AMReX also recommends writing primary floating point operation kernels
in C++ using AMReX’s Array4 object syntax. It provides a
multi-dimensional array syntax, similar in appearance to Fortran,
while maintaining performance. The details can be found in
Array4 and C++ Kernel.
Launching C++ nested loops
The most common AMReX work construct is a set of nested loops over the cells in a box. AMReX provides C++ functions and macro equivalents to port nested loops efficiently onto the GPU. There are 3 different nested loop GPU launches: a 4D launch for work over a box and a number of components, a 3D launch for work over a box and a 1D launch for work over a number of arbitrary elements. Each of these launches provides a performance portable set of nested loops for both CPU and GPU applications.
These loop launches should only be used when each iteration of the
nested loop is independent of other iterations. Therefore, these
launches have been marked with AMREX_PRAGMA_SIMD when using the
CPU and they should only be used for simd-capable nested loops.
Calculations that cannot vectorize should be rewritten wherever
possible to allow efficient utilization of GPU hardware.
For loops whose iterations are not independent, AMReX provides
amrex::For. It supports the same set of signatures as
amrex::ParallelFor (including the variants taking a
TypeList of CompileTimeOptions) and generates identical
code on GPU, but omits AMREX_PRAGMA_SIMD on CPU. A common case
requiring amrex::For is scatter-style accumulation with
Gpu::Atomic operations: on the host these compile to plain
(non-atomic) updates, so different iterations may update the same
memory location. Using amrex::ParallelFor for such a loop
licenses the compiler to vectorize it anyway, which can silently drop
updates from vector lanes that touch the same address.
However, it is important for applications to use these launches whenever appropriate because they contain optimizations for both CPU and GPU variations of nested loops. For example, on the GPU the spatial coordinate loops are reduced to a single loop and the component loop is moved to these innermost loops. AMReX’s launch functions apply the appropriate optimizations for compiling both with and without GPU support in a compact and readable format.
AMReX also provides a variation of the launch function that is implemented as a C++ macro. It behaves identically to the function, but hides the lambda function from the user. There are some subtle differences between the two implementations, that will be discussed. It is up to the user to select which version they would like to use. For simplicity, the function variation will be discussed throughout the rest of this documentation, however all code snippets will also include the macro variation for reference.
A 4D example of the launch function, amrex::ParallelFor, is given here:
int ncomp = mf.nComp();
for (MFIter mfi(mf,TilingIfNotGPU()); mfi.isValid(); ++mfi)
{
const Box& bx = mfi.tilebox();
Array4<Real> const& fab = mf.array(mfi);
amrex::ParallelFor(bx, ncomp,
[=] AMREX_GPU_DEVICE (int i, int j, int k, int n)
{
fab(i,j,k,n) += 1.;
});
/* MACRO VARIATION:
/
/ AMREX_PARALLEL_FOR_4D ( bx, ncomp, i, j, k, n,
/ {
/ fab(i,j,k,n) += 1.;
/ });
*/
}
This code works whether it is compiled for GPUs or CPUs. TilingIfNotGPU()
returns false in the GPU case to turn off tiling and maximize the amount of
work given to the GPU in each launch. When tiling is off, tilebox()
returns the validbox(). The BaseFab::array() function returns a
lightweight Array4 object that defines access to the underlying FArrayBox
data. The Array4s are then captured by the C++ lambda functions defined in the
launch function.
amrex::ParallelFor() expands into different variations of a quadruply-nested
for loop depending on dimensionality and whether it is being implemented on CPU or GPU.
The best way to understand this function is to take a look at the 4D amrex::ParallelFor
that is implemented when AMReX is compiled without GPU support, such as USE_CUDA=FALSE.
A simplified version is reproduced here:
void ParallelFor (Box const& box, int ncomp, /* LAMBDA FUNCTION */)
{
const Dim3 lo = amrex::lbound(box);
const Dim3 hi = amrex::ubound(box);
for (int n = 0; n < ncomp; ++n) {
for (int z = lo.z; z <= hi.z; ++z) {
for (int y = lo.y; y <= hi.y; ++y) {
AMREX_PRAGMA_SIMD
for (int x = lo.x; x <= hi.x; ++x) {
/* LAUNCH LAMBDA FUNCTION (x,y,z,n) */
}}}
}
}
amrex::ParallelFor takes a Box and a number of components, which define the bounds
of the quadruply-nested for loop, and a lambda function to run on each iteration of the
nested loop. The lambda function takes the loop iterators as parameters, allowing the current
cell to be indexed in the lambda. In addition to the loop indices, the lambda function captures
any necessary objects defined in the local scope.
CUDA lambda functions can only capture by value, as the information
must be able to be copied onto the device. In this example, the
lambda function captures a Array4 object, fab, that defines
how to access the FArrayBox. The macro uses fab to
increment the value of each cell within the Box bx. If
AMReX is compiled with GPU support, this incrementation is performed on the GPU, with
GPU optimized loops.
This 4D launch can also be used to work over any sequential set of components, by passing the
number of consecutive components and adding the iterator to the starting component:
fab(i,j,k,n_start+n).
The 3D variation of the loop launch does not include a component loop and has the syntax shown here:
for (MFIter mfi(mf,TilingIfNotGPU()); mfi.isValid(); ++mfi)
{
const Box& bx = mfi.tilebox();
Array4<Real> const& fab = mf.array(mfi);
amrex::ParallelFor(bx,
[=] AMREX_GPU_DEVICE (int i, int j, int k)
{
fab(i,j,k) += 1.;
});
/* MACRO VARIATION:
/
/ AMREX_PARALLEL_FOR_3D ( bx, i, j, k,
/ {
/ fab(i,j,k) += 1.;
/ });
*/
}
Finally, a 1D version is available for looping over a number of elements, such as particles. An example of a 1D function launch is given here:
for (MFIter mfi(mf); mfi.isValid(); ++mfi)
{
FArrayBox& fab = mf[mfi];
Real* AMREX_RESTRICT p = fab.dataPtr();
const long nitems = fab.box().numPts() * fab.nComp();
amrex::ParallelFor(nitems,
[=] AMREX_GPU_DEVICE (long idx)
{
p[idx] += 1.;
});
/* MACRO VARIATION:
/
/ AMREX_PARALLEL_FOR_1D ( nitems, idx,
/ {
/ p[idx] += 1.;
/ });
*/
}
Instead of passing an Array4, FArrayBox::dataPtr() is called to obtain a
pointer to the FArrayBox data. This is an alternative way to access
the FArrayBox data on the GPU. Instead of passing a Box to define the loop
bounds, a long or int number of elements is passed to bound the single
for loop. This construct can be used to work on any contiguous set of memory by
passing the number of elements to work on and indexing the pointer to the starting
element: p[idx + 15].
GPU block size
By default, ParallelFor launches AMREX_GPU_MAX_THREADS threads
per GPU block, where AMREX_GPU_MAX_THREADS is a compile-time constant
with a default value of 256. The users can also explicitly specify the
number of threads per block by ParallelFor<MY_BLOCK_SIZE>(...), where
MY_BLOCK_SIZE is a multiple of the warp size (e.g., 128). This allows
the users to do performance tuning for individual kernels.
Launching general kernels
To launch more general work on the GPU, AMReX provides a standard launch function:
amrex::launch. Instead of creating nested loops, this function
prepares the device launch based on a Box, launches with an appropriate sized
GPU kernel and constructs a thread Box that defines the work for each thread.
On the CPU, the thread Box is set equal to the total launch Box, so
tiling works as expected. On the GPU, the thread Box usually
contains a single cell to allow all GPU threads to be utilized effectively.
An example of a generic function launch is shown here:
for (MFIter mfi(mf,TilingIfNotGPU()); mfi.isValid(); ++mfi)
{
const Box& bx = mfi.tilebox();
Array4<Real> const& arr = mf.array(mfi);
amrex::launch(bx,
[=] AMREX_GPU_DEVICE (Box const& tbx)
{
pluseone_array4(tbx, arr);
FArrayBox fab(arr, tbx.ixType());
plusone_fab(tbx, fab); // this version takes FArrayBox
});
/* MACRO VARIATION
/
/ AMREX_LAUNCH_DEVICE_LAMBDA ( bx, tbx,
/ {
/ plusone_array4(tbx, arr);
/ plusone_fab(tbx, FArrayBox(arr,tbx.ixType()));
/ });
*/
}
It also shows how to make a FArrayBox from Array4 when
needed. Note that FarrayBoxes cannot be passed to GPU
kernels directly. TilingIfNotGPU() returns false in the
GPU case to turn off tiling and maximize the amount of work given to
the GPU in each launch, which substantially improves performance.
When tiling is off, tilebox() returns the validbox() of
the FArrayBox for that iteration.
Offloading work using OpenACC or OpenMP pragmas
When using OpenACC or OpenMP with AMReX, the GPU offloading work is done
with pragmas placed on the nested loops. This leaves the MFIter loop
largely unchanged. An example GPU pragma based MFIter loop that calls
a Fortran function is given here:
for (MFIter mfi(mf,TilingIfNotGPU()); mfi.isValid(); ++mfi)
{
const Box& bx = mfi.tilebox();
FArrayBox& fab = mf[mfi];
plusone_acc(BL_TO_FORTRAN_BOX(tbx),
BL_TO_FORTRAN_ANYD(fab));
}
The function plusone_acc is a CPU host function. The
FArrayBox reference
from operator[] is a reference to a FArrayBox in host
memory with data that has been placed in GPU memory.
BL_TO_FORTRAN_BOX and BL_TO_FORTRAN_ANYD behave identically
to implementations used on the CPU. These macros return the
individual components of the AMReX C++ objects to allow passing to
the Fortran function.
The corresponding OpenACC labeled loop in plusone_acc is:
!dat = pointer to fab's GPU data
!$acc kernels deviceptr(dat)
do k = lo(3), hi(3)
do j = lo(2), hi(2)
do i = lo(1), hi(1)
dat(i,j,k) = dat(i,j,k) + 1.0_amrex_real
end do
end do
end do
!$acc end kernels
Since the data pointer passed to plusone_acc points to
device memory, OpenACC can be told the data is available on the
device using the deviceptr construct. For further details
about OpenACC programming, consult the OpenACC user’s guide.
The OpenMP implementation of this loop is similar, only requiring changing the pragmas utilized to obtain the proper offloading. The OpenMP labeled version of this loop is:
!dat = pointer to fab's GPU data
!$omp target teams distribute parallel do collapse(3) schedule(static,1) is_device_ptr(dat)
do k = lo(3), hi(3)
do j = lo(2), hi(2)
do i = lo(1), hi(1)
dat(i,j,k) = dat(i,j,k) + 1.0_amrex_real
end do
end do
end do
In this case, is_device_ptr is used to indicate that dat
is available in device memory. For further details about programming
with OpenMP for GPU offloading, consult the OpenMP user’s guide.
Kernel launch details
CUDA (and HIP) kernel calls are asynchronous and they return before the kernel
is finished on the GPU. So the MFIter loop finishes iterating on
the CPU and is ready to move on to the next work before the actual
work completes on the GPU. To guarantee consistency,
there is an implicit device synchronization (a GPU barrier) in
the destructor of MFIter. This ensures that all GPU work
inside of an MFIter loop will complete before code outside of
the loop is executed. Any kernel launches made outside of an
MFIter loop must ensure appropriate device synchronization
occurs. This can be done by calling Gpu::streamSynchronize().
CUDA and HIP supports multiple streams and kernels. Kernels launched in the
same stream are executed sequentially, but different streams of kernel
launches may be run in parallel. For each iteration of MFIter,
AMReX uses a different GPU stream (up to 4 streams in total). This
allows each iteration of an MFIter loop to run independently,
but in the expected sequence, and maximize the use of GPU parallelism.
However, AMReX uses the default GPU stream outside of MFIter
loops.
Launching kernels with AMReX’s launch macros or functions implement a C++ lambda function. Lambda functions used for launches on the GPU have some restrictions the user must understand. First, the function enclosing the extended lambda must not have private or protected access within its parent class, otherwise the code will not compile. This can be fixed by changing the access of the enclosing function to public.
Another pitfall that must be considered: if the lambda function
accesses a member of the enclosing class, the lambda function actually
captures this pointer by value and accesses variables and functions
via this->. If the object is not accessible on GPU, the code will
not work as intended. For example,
class MyClass {
public:
Box bx;
int m; // integer created on the host.
void f () {
amrex::ParallelFor(bx,
[=] AMREX_GPU_DEVICE (int i, int j, int k)
{
printf("m = %d\n", m); // Failed attempt to use m on the GPU.
});
}
};
The function f in the code above will not work unless the MyClass
object is in unified memory. If it is undesirable to put the object into
unified memory, a local copy of the information can be created for the
lambda to capture. For example:
class MyClass {
public:
Box bx;
int m;
void f () {
int local_m = m; // Local temporary copy of m.
amrex::ParallelFor(bx,
[=] AMREX_GPU_DEVICE (int i, int j, int k)
{
printf("m = %d\n", local_m); // Lambda captures local_m by value.
});
}
};
C++ macros have some important limitations. For example, commas outside of a set of parentheses are interpreted by the macro, leading to errors such as:
AMREX_PARALLEL_FOR_3D (bx, tbx,
{
Real a, b; <---- Error. Macro reads "{ Real a" as a parameter
and "b; }" as
another.
Real a; <---- OK
Real b;
});
One should also avoid using continue and return inside the macros
because it is not an actual for loop.
Users that choose to implement the macro launches should be aware of the limitations
of C++ preprocessing macros to ensure GPU offloading is done properly.
Finally, AMReX’s most common CPU threading strategy for GPU/CPU systems is to utilize
OpenMP threads to maintain multi-threaded parallelism on work chosen to run on the host.
This means OpenMP pragmas should be maintained where CPU work is performed and usually
turned off where work is offloaded onto the GPU. OpenMP pragmas can be turned
off using the conditional pragma and Gpu::notInLaunchRegion(), as shown below:
#ifdef AMREX_USE_OMP
#pragma omp parallel if (Gpu::notInLaunchRegion())
#endif
It is generally expected that simply using OpenMP threads to launch GPU work quicker will show little improvement or even perform worse. So, this conditional statement should be added to MFIter loops that contain GPU work, unless users specifically test the performance or are designing more complex workflows that require OpenMP.
Stream and Synchronization
As mentioned in Section Overview of AMReX GPU Support, AMReX uses a number of GPU
streams that are either CUDA streams or HIP streams or SYCL queues. Many
GPU functions (e.g., ParallelFor and Gpu::copyAsync) are
asynchronous with respect to the host. To facilitate synchronization that
is sometimes necessary, AMReX provides Gpu::streamSynchronize() and
Gpu::streamSynchronizeAll() to synchronize the current stream and all
AMReX streams, respectively. For performance reasons, one should try to
minimize the number of synchronization calls. For example,
// The synchronous version is NOT recommended
Gpu::copy(Gpu::deviceToHost, ....);
Gpu::copy(Gpu::deviceToHost, ....);
Gpu::copy(Gpu::deviceToHost, ....);
// NOT recommended because of unnecessary synchronization
Gpu::copyAsync(Gpu::deviceToHost, ....);
Gpu::streamSynchronize();
Gpu::copyAsync(Gpu::deviceToHost, ....);
Gpu::streamSynchronize();
Gpu::copyAsync(Gpu::deviceToHost, ....);
Gpu::streamSynchronize();
// recommended
Gpu::copyAsync(Gpu::deviceToHost, ....);
Gpu::copyAsync(Gpu::deviceToHost, ....);
Gpu::copyAsync(Gpu::deviceToHost, ....);
Gpu::streamSynchronize();
In addition to stream synchronization, there is also
Gpu::synchronize() that will perform a device wide synchronization.
However, a device wide synchronization is usually too excessive and it might
interfere with other libraries (e.g., MPI).
AMReX functions can exhibit different synchronization behaviors. Functions
that launch user-provided GPU kernels are typically asynchronous. For
example, GPU kernels launched by the ParallelFor family of functions
(including variants for 1D arrays, Boxes, and an entire
MultiFab in a single kernel) are asynchronous with respect to the
host.
The only exception in the ParallelFor family is
ParallelForRNG, which is used when random number generation is
required inside the GPU kernel. It contains an implicit stream
synchronization to avoid potential race conditions. Many member functions of
BaseFab and FArrayBox are also asynchronous. However, implicit
synchronizations occur in a number of situations. Some are unavoidable. For
example, Reduce::Sum returns a value on the host, and therefore must
perform an implicit synchronization. Another example is the communication
functions such as FillBoundary. Since MPI has no notion of GPU
streams, the data must be synchronized before being passed to MPI calls.
Other synchronizations are introduced for safety. A notable example is
MFIter, which performs implicit synchronizations at both the
beginning and end of the loop (as a whole, not on each iteration). These
synchronizations can be disabled using MFItInfo. For example,
// There is no implicit synchronization in the following loop.
for (MFIter mfi(mf, MFItInfo{}.DisableDeviceSync()); mfi.isValid(); ++mfi)
{ ... }
One could also use Gpu::NoSyncRegion, as shown below:
{
Gpu::NoSyncRegion no_sync{}; // No implicit GPU synchronization in the
// current scope
for (MFIter mfi(mf); mfi.isValid(); ++mfi) { ... }
// Gpu::streamSynchronize(); Explicit synchronization is allowed.
for (MFIter mfi(mf2); mfi.isValid9); ++mfi) { .... }
}
This approach suppresses implicit synchronization for all operations within the scoped region and restores the previous synchronization setting upon exiting.
External GPU Streams
AMReX normally launches GPU kernels from an internal pool of GPU streams and
round-robins across them inside MFIter loops. When an application
needs to integrate with an externally managed stream, AMReX provides an
override mechanism. External-stream overrides form a stack and all calls
must occur outside OpenMP parallel regions. If you install a new external
stream while another is already active, the new handle becomes current until
it is reset, at which point AMReX restores the previous external stream.
Call
amrex::Gpu::setExternalGpuStream(stream)(or use the RAII helperamrex::Gpu::ExternalGpuStreamRegion(stream,sync_on_exit)) on the host. Every subsequent call toamrex::Gpu::gpuStream()returns the supplied stream. Calls must be paired withamrex::Gpu::resetExternalGpuStream(sync_stream)(RAII helpers pass the same flag viasync_on_exit); popping the current stream restores the previous external stream, if any. Passingamrex::Gpu::ExternalStreamSync::Notosync_stream/sync_on_exitskips the finalGpu::streamSynchronizeunless deferred frees recorded byThe_Async_Arenaare still pending, in which case AMReX forces a synchronization to keep the arena safe. The external stream or queue must belong to the active AMReX device. For SYCL, the queue must also use the same SYCL context as AMReX and must be an in-order queue. AMReX selects the active GPU duringamrex::Initialize, whose overloads accept an optional trailingint device_idargument; pass the desired GPU there if an external runtime needs AMReX to adopt a specific device before the stream is created. Conversely, if AMReX should drive the selection, queryamrex::Gpu::Device::deviceId()and configure the external runtime (for example, by callingcudaSetDeviceorhipSetDevicebefore constructing the stream) so that the stream is associated with the device AMReX is already using.All asynchronous frees recorded through
amrex::Gpu::freeAsyncand The_Async_Arena continue to work because AMReX tracks the external stream with an internalStreamManager.
Limitations and best practices:
Entering or exiting the override inside an OpenMP parallel region is illegal and will trigger an assertion. Configure the stream on the main thread before launching GPU work, if OpenMP threading is used.
Backend compatibility rules are checked when the override is installed. CUDA and HIP external streams must be associated with the current
amrex::Gpu::Device::deviceId(). SYCL external queues must use AMReX’s SYCL device and SYCL context, and must be in-order.While an override is active,
Gpu::numGpuStreams()reports1. This keepsMFIterfrom trying to pipeline across multiple AMReX-managed streams, but it also means you cannot currently provide a set of external streams for MFIter to round-robin across.Objects that use stream-ordered memory (for example, a
BaseFaballocated fromThe_Async_Arena) should generally be created and destroyed within the same external-stream region. In particular, avoid creating or resizing such an object inside an external-stream region and then destroying it after that region has exited, or creating it outside and then resizing or destroying it inside the region. Stream-ordered frees remember the stream associated with the allocation, and AMReX requires that stream to still be managed when the free occurs. If that stream was external and has already been popped, AMReX aborts instead of guessing where to enqueue the deferred free.Likewise, reuse a given
ReducerorReduceDataobject only on a single external stream. Reusing the same object across different external stream regions, or across an external stream and AMReX stream 0, is not supported. If a reduction is launched inside an external-stream region, read its final value before leaving that region.Make sure the external stream remains valid for the duration of the override. Destroying it before the RAII guard goes out of scope is undefined behavior.
Using
ExternalStreamSync::Notransfers synchronization responsibility to the caller. AfterresetExternalGpuStream(ExternalStreamSync::No), AMReX no longer tracks that external stream, and later AMReX global synchronization helpers are not guaranteed to wait for work already queued on it. It is the user’s responsibility to synchronize that external stream before any dependent teardown or finalization.
Example: wrap AMReX work inside an externally created CUDA stream:
#ifdef AMREX_USE_CUDA
cudaStream_t external{};
AMREX_CUDA_SAFE_CALL(cudaStreamCreateWithFlags(&external, cudaStreamNonBlocking));
#endif
{
amrex::Gpu::ExternalGpuStreamRegion stream_scope(external);
MultiFab mf(...);
MFItInfo info;
info.DisableDeviceSync();
for (MFIter mfi(mf,info); mfi.isValid(); ++mfi) {
auto const& box = mfi.tilebox();
auto const arr = mf.array(mfi);
amrex::ParallelFor(box, [=] AMReX_GPU_DEVICE (int i, int j, int k) {
arr(i,j,k) = 0.0_rt;
});
}
// Optional: launch non-AMReX CUDA kernels on 'external' here.
}
#ifdef AMREX_USE_CUDA
AMREX_CUDA_SAFE_CALL(cudaStreamDestroy(external));
#endif
The same pattern works for HIP streams and, in SYCL builds, with
sycl::queue objects.
An Example of Migrating to GPU
The nature of GPU programming poses difficulties for a number of common AMReX patterns, such as the one below:
// Given MultiFab uin and uout
#ifdef AMREX_USE_OMP
#pragma omp parallel
#endif
{
FArrayBox q;
for (MFIter mfi(uin,true); mfi.isValid(); ++mfi)
{
const Box& tbx = mfi.tilebox();
const Box& gbx = amrex::grow(tbx,1);
q.resize(gbx);
// Do some work with uin[mfi] as input and q as output.
// The output region is gbx;
f1(gbx, q, uin[mfi]);
// Then do more work with q as input and uout[mfi] as output.
// The output region is tbx.
f2(tbx, uout[mfi], q);
}
}
There are several issues in migrating this code to GPUs that need to
be addressed. First, functions f1 and f2 have different
work regions (tbx and gbx, respectively) and there are data
dependencies between the two (q). This makes it difficult to put
them into a single GPU kernel, so two separate kernels will be
launched, one for each function.
As we have discussed, AMReX uses multiple CUDA streams or HIP streams
or SYCL queues for launching
kernels. Because q is used inside MFIter loops, multiple
GPU kernels on different streams are accessing its data. This creates
a race condition. One way to fix this is to move FArrayBox q
inside the loop to make it local to each loop and use Elixir to
make it async-safe (see Section Elixir). This
strategy works well for GPU. However it is not optimal for OpenMP CPU
threads when the GPU is not used, because of the memory allocation inside
OpenMP parallel region. It turns out it is actually unnecessary to
make FArrayBox q local to each iteration when Elixir is
used to extend the life of its floating point data. The code below
shows an example of how to rewrite the example in a performance
portable way.
// Given MultiFab uin and uout
#ifdef AMREX_USE_OMP
#pragma omp parallel if (Gpu::notInLaunchRegion())
#endif
{
FArrayBox q;
for (MFIter mfi(uin,TilingIfNotGPU()); mfi.isValid(); ++mfi)
{
const Box& tbx = mfi.tilebox();
const Box& gbx = amrex::grow(tbx,1);
q.resize(gbx);
Elixir eli = q.elixir();
Array4<Real> const& qarr = q.array();
Array4<Real const> const& uinarr = uin.const_array(mfi);
Array4<Real> const& uoutarr = uout.array(mfi);
amrex::launch(gbx,
[=] AMREX_GPU_DEVICE (Box const& b)
{
f1(b, qarr, uinarr);
});
amrex::launch(tbx,
[=] AMREX_GPU_DEVICE (Box const& b)
{
f2(b, uoutarr, qarr);
});
}
}
Assertions and Error Checking
To help debugging, we often use amrex::Assert and
amrex::Abort. These functions are GPU safe and can be used in
GPU kernels. However, implementing these functions requires additional
GPU registers, which will reduce overall performance. Therefore, by
default these functions and the macro AMREX_ALWAYS_ASSERT are no-ops
for optimized builds (e.g., DEBUG=FALSE using the GNU Make build
system) when called from kernels run on GPU. Calls to these functions from
GPU kernels are active for debug builds and can optionally be activated
at compile time for optimized builds (e.g., DEBUG=FALSE and
USE_ASSERTION=TRUE using the GNU Make build system).
In CPU code, AMREX_GPU_ERROR_CHECK() can be called
to check the health of previous GPU launches. This call
looks up the return message from the most recently completed GPU
launch and aborts if it was not successful. Many kernel
launch macros as well as the MFIter destructor include a call
to AMREX_GPU_ERROR_CHECK(). This prevents additional launches
from being called if a previous launch caused an error and ensures
all GPU launches within an MFIter loop completed successfully
before continuing work.
However, due to asynchronicity, determining the source of the error
can be difficult. Even if GPU kernels launched earlier in the code
result in a CUDA error or HIP error, the error may not be output at
a nearby call to AMREX_GPU_ERROR_CHECK() by the CPU.
When tracking down a CUDA launch error, Gpu::synchronize(),
Gpu::streamSynchronize(), or Gpu::streamSynchronizeAll() can
be used to synchronize the device, the current GPU stream, or all GPU
streams, respectively, and track down the specific launch that causes the
error. This error-checking macro will not return any information for SYCL.
Particle Support
As with MultiFab, particle data stored in AMReX ParticleContainer classes can be
stored in GPU-accessible memory when AMReX is compiled with GPU support. The type of memory used by a given ParticleContainer can be controlled
by the Allocator template parameter. By default, when compiled with GPU support ParticleContainer uses The_Arena(). This means that the dataPtr associated with particle data
can be passed into GPU kernels. These kernels can be launched with a variety of approaches,
including AMReX’s native kernel launching mechanisms as well OpenMP and OpenACC. Using AMReX’s C++ syntax, a kernel launch involving particle data might look like:
for(MyParIter pti(pc, lev); pti.isValid(); ++pti)
{
auto& ptile = pti.GetParticleTile();
auto ptd = tile.getParticleTileData();
const auto np = tile.numParticles();
amrex::ParallelFor( np,
[=] AMREX_GPU_DEVICE (const int ip) noexcept
{
ptd.id(i).make_invalid();
});
}
The above code simply invalidates all particle on all particle tiles. The ParticleTileData
object is analogous to Array4 in that it stores pointers to particle data and can be used
on either the host or the device. This is a convenient way to pass particle data into GPU kernels
because the same object can be used regardless of whether the data layout is AoS or SoA.
An example Fortran particle subroutine offloaded via OpenACC might look like the following:
subroutine push_position_boris(np, structs, uxp, uyp, uzp, gaminv, dt)
use em_particle_module, only : particle_t
use amrex_fort_module, only : amrex_real
implicit none
integer, intent(in), value :: np
type(particle_t), intent(inout) :: structs(np)
real(amrex_real), intent(in) :: uxp(np), uyp(np), uzp(np), gaminv(np)
real(amrex_real), intent(in), value :: dt
integer :: ip
!$acc parallel deviceptr(structs, uxp, uyp, uzp, gaminv)
!$acc loop gang vector
do ip = 1, np
structs(ip)%pos(1) = structs(ip)%pos(1) + uxp(ip)*gaminv(ip)*dt
structs(ip)%pos(2) = structs(ip)%pos(2) + uyp(ip)*gaminv(ip)*dt
structs(ip)%pos(3) = structs(ip)%pos(3) + uzp(ip)*gaminv(ip)*dt
end do
!$acc end loop
!$acc end parallel
end subroutine push_position_boris
Note the use of the !$acc parallel deviceptr clause to specify which data has been placed
in device memory. This instructs OpenACC to treat those variables as if they already live on
the device, bypassing the usual copies. For complete examples of a particle code that has been ported
to GPUs using Cuda, OpenACC, and OpenMP, please see the tutorial Electromagnetic PIC.
GPU-aware implementations of many common particle operations are provided with AMReX, including neighbor list
construction and traversal, particle-mesh deposition and interpolation, parallel reductions of particle data,
and a set of transformation and filtering operations that are useful when operating on sets of particles. For
examples of these features in use, please see Tests/Particles/.
Finally, the parallel communication of particle data has been ported and optimized for performance on GPU
platforms. This includes Redistribute(), which moves particles back to the proper grids after their positions
have changed, as well as fillNeighbors() and updateNeighbors(), which are used to exchange halo particles.
As with MultiFab data, these have been designed to minimize host / device traffic as much as possible, and can
take advantage of the GPU-aware MPI implementations available on platforms such as ORNL’s Frontier.
Profiling with GPUs
When profiling for GPUs, AMReX recommends nvprof, NVIDIA’s visual
profiler. nvprof returns data on how long each kernel launch lasted on
the GPU, the number of threads and registers used, the occupancy of the GPU
and recommendations for improving the code. For more information on how to
use nvprof, see NVIDIA’s User’s Guide as well as the help web pages of
your favorite supercomputing facility that uses NVIDIA GPUs.
AMReX’s internal profilers currently cannot hook into profiling information on the GPU and an efficient way to time and retrieve that information is being explored. In the meantime, AMReX’s timers can be used to report some generic timers that are useful in categorizing an application.
Due to the asynchronous launching of GPU kernels, any AMReX timers inside of
asynchronous regions or inside GPU kernels will not measure useful
information. However, since the MFIter synchronizes when being
destroyed, any timer wrapped around an MFIter loop will yield a
consistent timing of the entire set of GPU launches contained within. For
example:
BL_PROFILE_VAR("A_NAME", blp); // Profiling start
for (MFIter mfi(mf); mfi.isValid(); ++mfi)
{
// gpu works
}
BL_PROFILE_STOP(blp); // Profiling stop
For now, this is the best way to profile GPU codes using TinyProfiler.
If you require further profiling detail, use nvprof.
Performance Tips
Here are some helpful performance tips to keep in mind when working with AMReX for GPUs:
To obtain the best performance when using CUDA kernel launches, all device functions called within the launch region should be inlined. Inlined functions use substantially fewer registers, freeing up GPU resources to perform other tasks. This increases parallel performance and greatly reduces runtime. Functions are written inline by putting their definitions in the
.Hfile and using theAMREX_FORCE_INLINEAMReX macro. Examples can be found in the Launch tutorial. For example:
AMREX_GPU_DEVICE
AMREX_FORCE_INLINE
void plusone_cudacpp (amrex::Box const& bx, amrex::FArrayBox& fab)
{
...
}
Pay attention to what GPUs your job scheduler is assigning to each MPI rank. In most cases you’ll achieve the best performance when a single MPI rank is assigned to each GPU, and has boxes large enough to saturate that GPU’s compute capacity. While there are some cases where multiple MPI ranks per GPU can make sense (typically this would be when you have some portion of your code that is not GPU accelerated and want to have many MPI ranks to make that part faster), this is probably the minority of cases. For example, on OLCF Summit you would want to ensure that your resource sets contain one MPI rank and GPU each, using jsrun -n N -a 1 -c 7 -g 1, where N is the total number of MPI ranks/GPUs you want to use. (See the OLCF [job step viewer](https://jobstepviewer.olcf.ornl.gov/) for more information.)
Conversely, if you choose to have multiple GPUs visible to each MPI rank, AMReX will attempt to do the best job it can assigning MPI ranks to GPUs by doing round robin assignment. This may be suboptimal because this assignment scheme would not be aware of locality benefits that come from having an MPI rank be on the same socket as the GPU it is managing.
Inputs Parameters
The following inputs parameters control the behavior of amrex when running on GPUs. They should be prefaced
by “amrex” in your inputs file.
Description |
Type |
Default |
|
|---|---|---|---|
use_gpu_aware_mpi |
Whether to use GPU memory for communication buffers during MPI calls. If true, the buffers will use device memory. If false (i.e., 0), they will use pinned memory. It will be activated if AMReX detects that GPU-aware MPI is supported by the MPI library (MPICH, OpenMPI, and derivative implementations). |
Bool |
MPI-dependent |
abort_on_out_of_gpu_memory |
If the size of free memory on the GPU is less than the size of a requested allocation, AMReX will call AMReX::Abort() with an error describing how much free memory there is and what was requested. |
Bool |
0 |
the_arena_is_managed |
Whether |
Bool |
0 |